
- Courses
- Android App Penetration Testing
- Android Application Development
- Blockchain for Beginners
- Big Data with Hadoop
- Web Application Penetration Testing (Bug Bounty)
- Cloud Computing with AWS
- Django
- Ethical Hacking
- Ethical Hacking (in Hindi)
- Industrial Automation with PLC
- Java Programming
- Javascript
- Linux Basic
- Machine Learning
- Machine Learning & Neural Network
- Penetration Testing
- Python Programming
- Advance Python Programming
- Penetration Testing (in Hindi)
- Web Development with HTML/CSS
- Web Development with WordPress
- Offline Workshops
Llama 3
Meta recently introduced their new family of large language models (LLMs) called Llama 3. This release includes 8B and 70B parameters pre-trained and instruction-tuned models.
Llama 3 Architecture Details
Here is a summary of the mentioned technical details of Llama 3:
- It uses a standard decoder-only transformer.
- The vocabulary is 128K tokens.
- It is trained on sequences of 8K tokens.
- It applies grouped query attention (GQA)
- It is pretrained on over 15T tokens.
- It involves post-training that includes a combination of SFT, rejection sampling, PPO, and DPO.
Performance
Notably, Llama 3 8B (instruction-tuned) outperforms Gemma 7B and Mistral 7B Instruct. Llama 3 70 broadly outperforms Gemini Pro 1.5 and Claude 3 Sonnet and falls a bit behind on the MATH benchmark when compared to Gemini Pro 1.5.
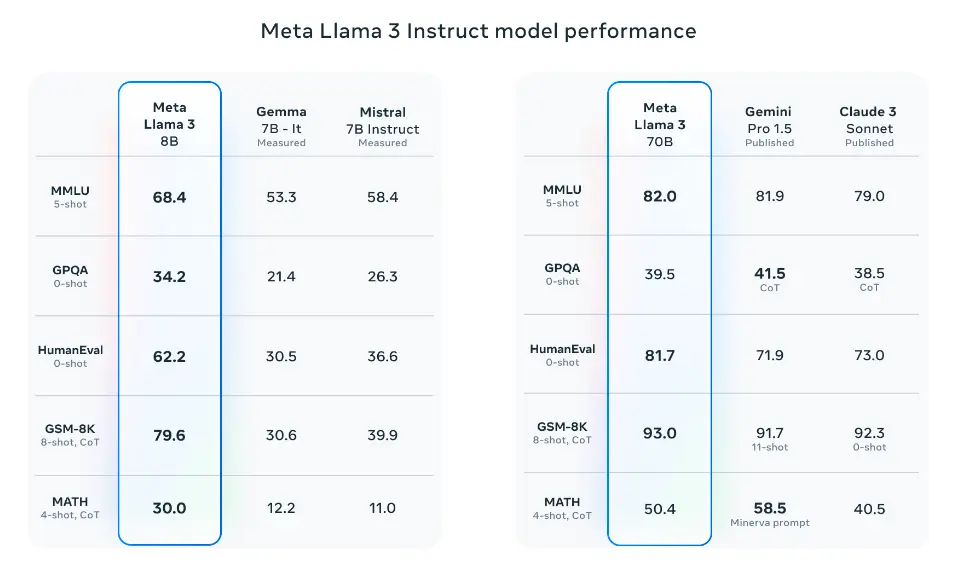
Source: Meta AI
The pretrained models also outperform other models on several benchmarks like AGIEval (English), MMLU, and Big-Bench Hard.
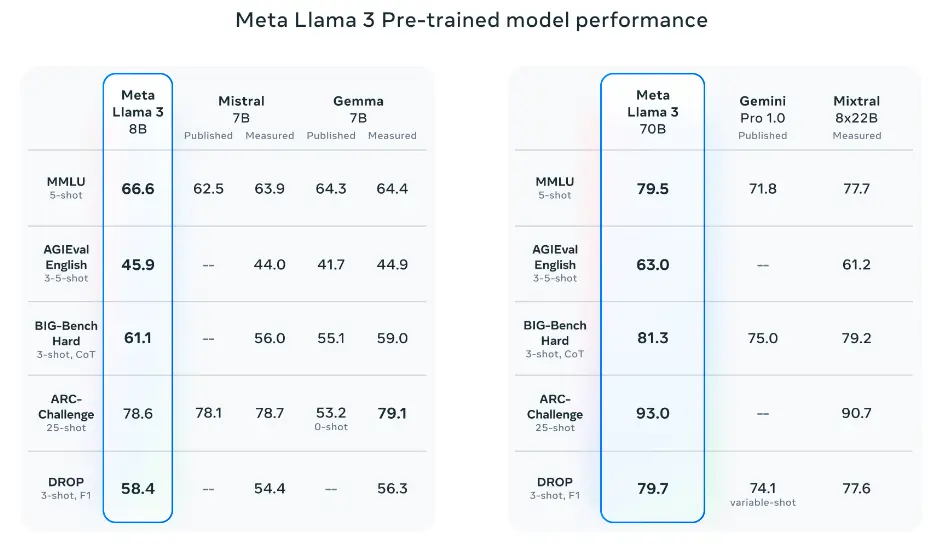
Source: Meta AI
Llama 3 400B
Meta also reported that they will be releasing a 400B parameter model which is still training and coming soon! There are also efforts around multimodal support, multilingual capabilities, and longer context windows in the pipeline. The current checkpoint for Llama 3 400B (as of April 15, 2024) produces the following results on the common benchmarks like MMLU and Big-Bench Hard:
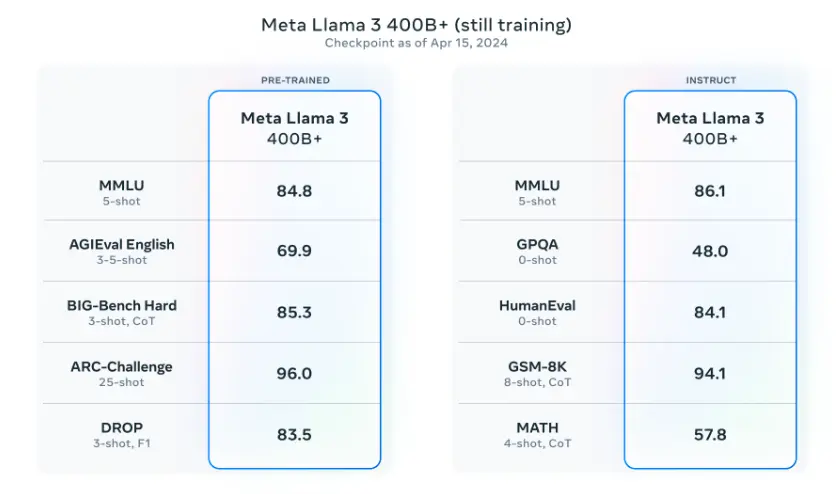
Source: Meta AI
The licensing information for the Llama 3 models can be found on the model card.
Extended Review of Llama 3
Here is a longer review of Llama 3: